Facebook research team’s fastText library provides useful methods for text classification.
In this article, We use facebookresearch/fastText and trained model for language identification.
Source codes are available on GitHub.
AWS Layers
First, prepare fastText library and trained language models as layers to reduce the size of deployment packages.
Layer 1 - fastText using fasttext-wheel
We install the fastText library using the fasttext-wheel python package.
Information
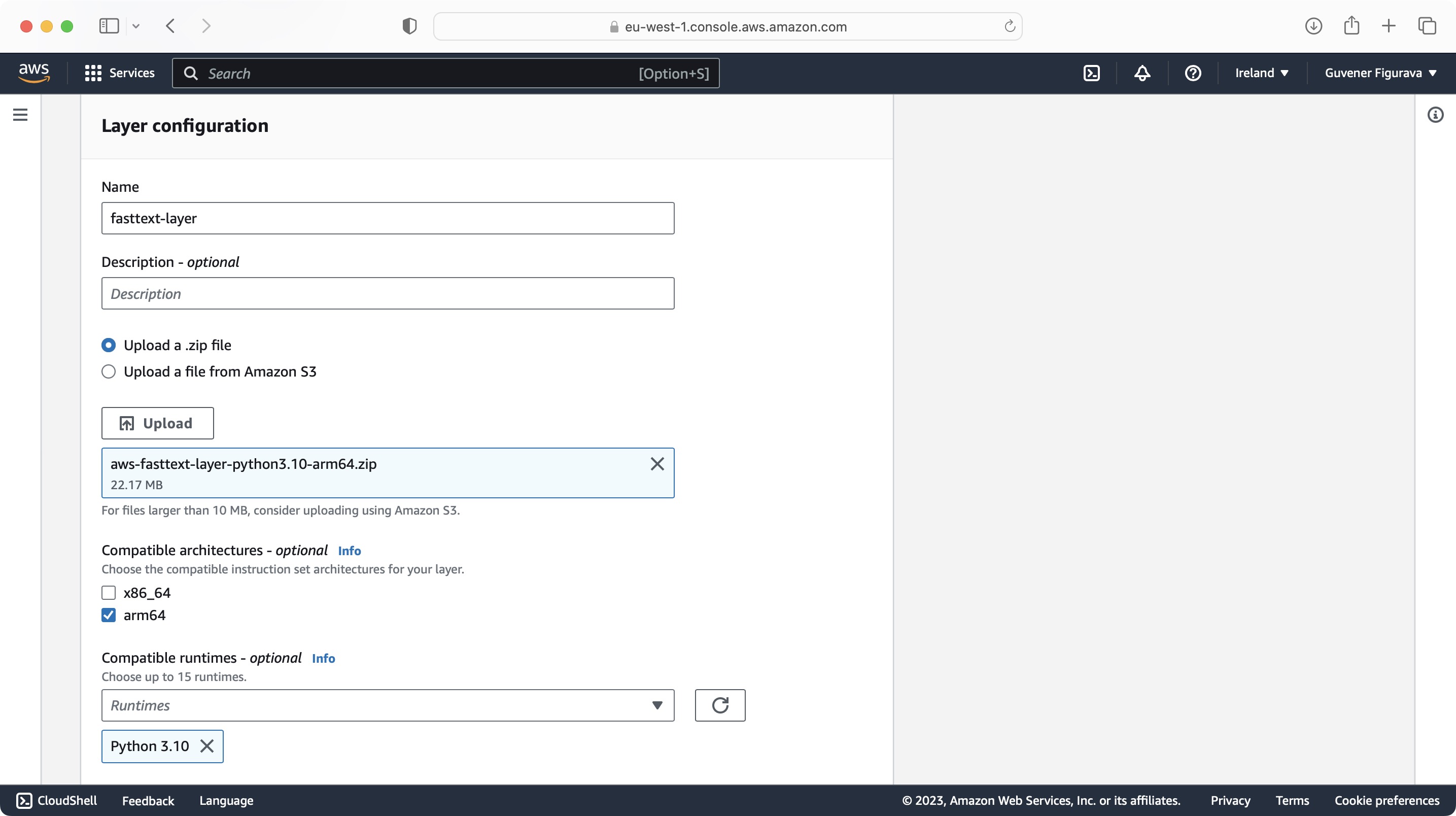
aws-fasttext-layer-python3.10-arm64.zip layer provided in GitHub repository is prepared for Python 3.10 runtime and uses arm64 architecture.
You can create a layer by uploading the zip file with the given configuration or build your own using the instructions below.
docker run -it ubuntuThe flag -it is used to open an interactive shell.
apt update
apt install python3.10
apt install python3-pip
# Use pip install
mkdir -p layer/python/lib/python3.10/site-packages
pip3 install fasttext-wheel -t layer/python/lib/python3.10/site-packages/
cd layer
# apt install zip
zip -r mypackage.zip *
# Now we have to copy the zip file mypackage.zip to our local folder.
# open a new command prompt and get the container ID by running:
docker ps -a
docker cp <Container-ID:path_of_zip_file>
# for example:
docker cp 79e3e2cdc863:/layer/mypackage.zip /Users/guvenergokceLayer 2 - Language identification model
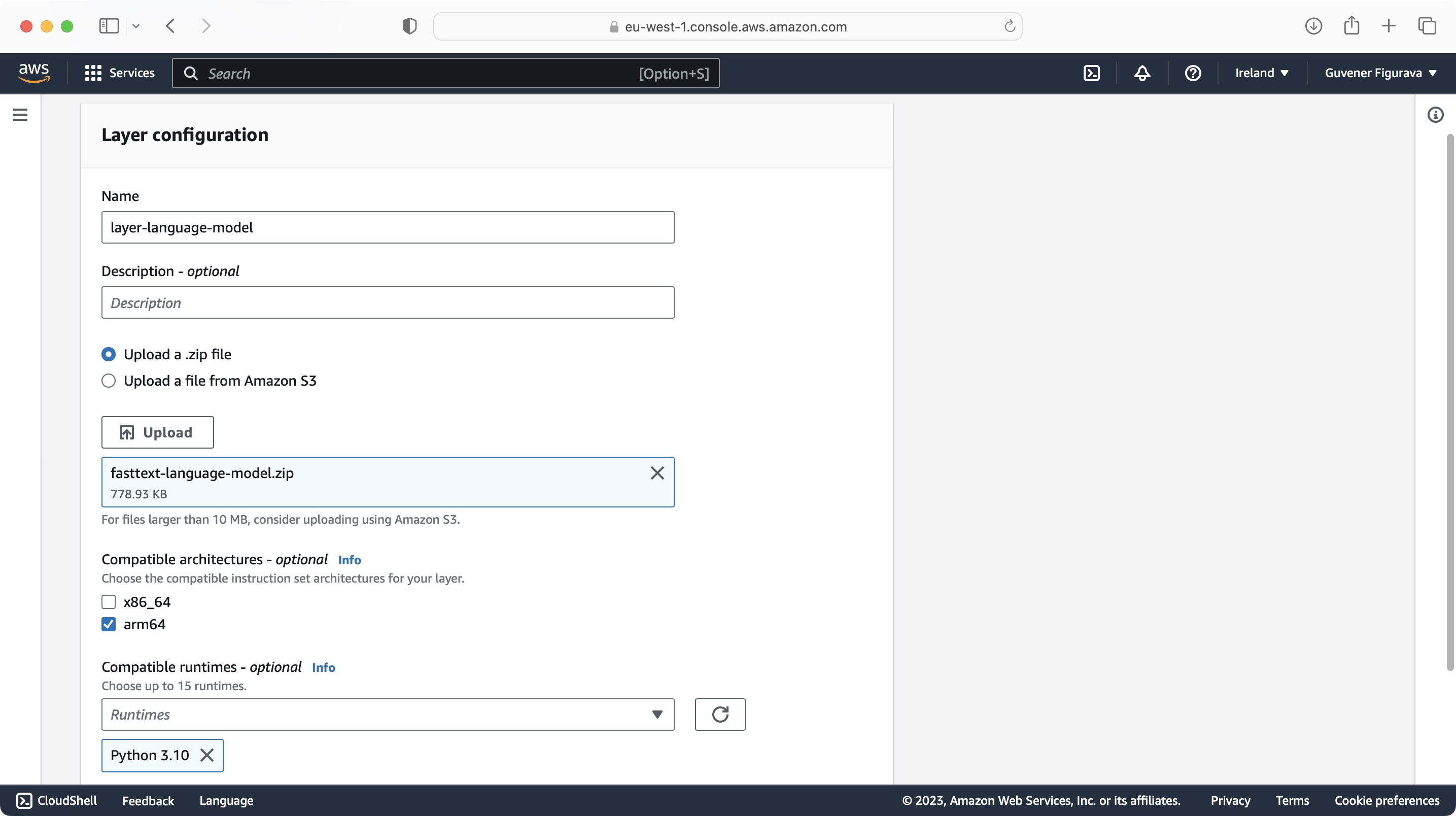
There are two trained models: lid.176.bin is more accurate, but it requires uploading to an S3 bucket due to its large file size.
fasttext-language-model.zip file provided in GitHub repository uses light pre trained model lid.176.ftz, replace lid.176.ftz with lid.176.bin in case you prepare large model as below.
# create a pretrained folder, download model from fbai's public files and zip folder.
mkdir pretrained
cd pretrained
curl -O https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.bin
cd ..
zip -r fasttext-language-model.zip pretrainedYou can consider using lid.176.ftz for creating a light layer and uploding directly from browser.
When you add a layer to a function, Lambda loads the layer content into the /opt directory of that execution environment. Working with Lambda layers
When your layer is loaded, you will find your model in /opt/pretrained/lid.176.bin path.
Deploy on AWS
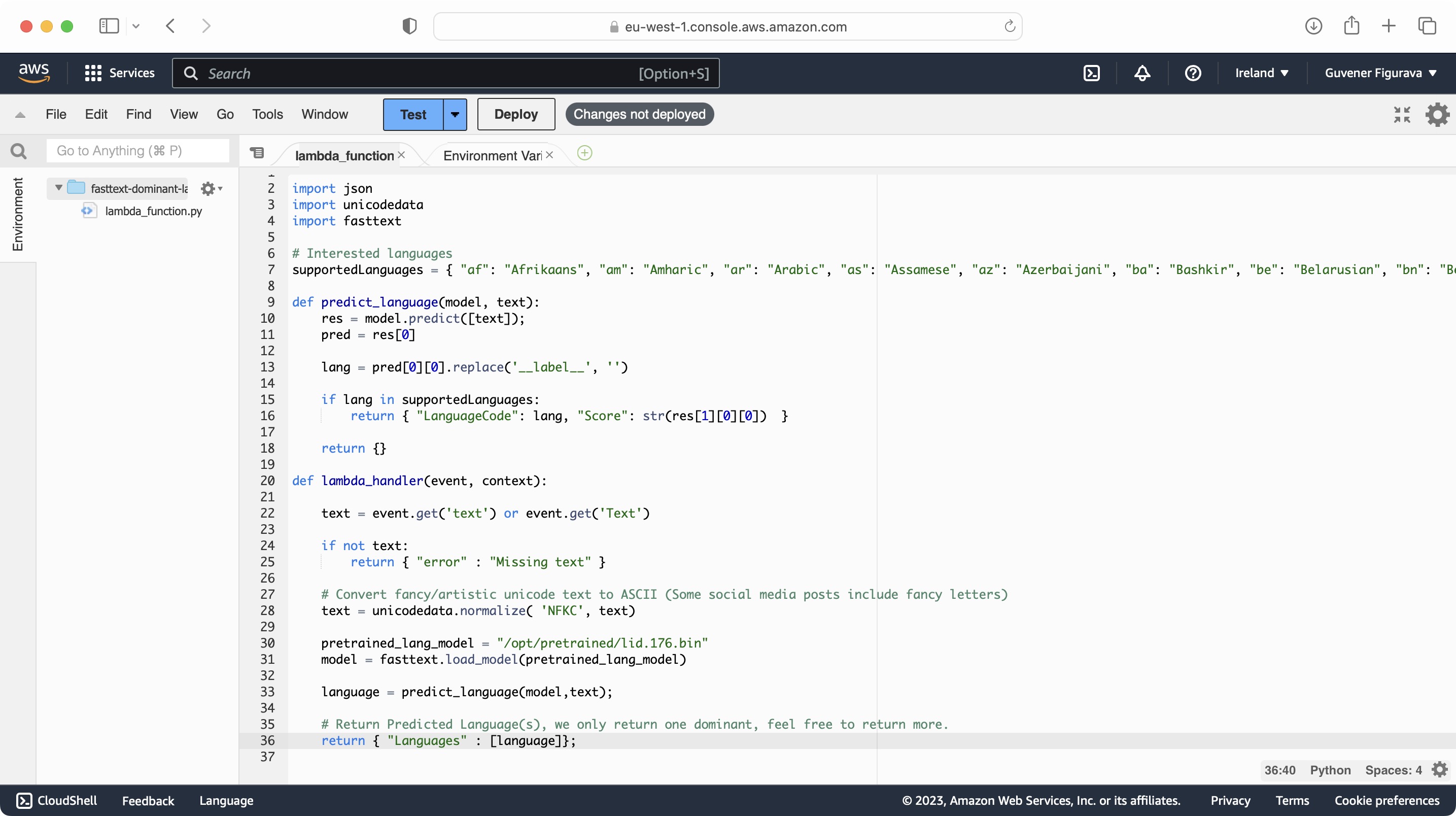
Lambda function handler in Python
Process incoming events with handler.py
import json
import unicodedata
import fasttext
# Interested languages
supportedLanguages = { "af": "Afrikaans", "am": "Amharic", "ar": "Arabic", "as": "Assamese", "az": "Azerbaijani", "ba": "Bashkir", "be": "Belarusian", "bn": "Bengali", "bs": "Bosnian", "bg": "Bulgarian", "ca": "Catalan", "ceb": "Cebuano", "cs": "Czech", "cv": "Chuvash", "cy": "Welsh", "da": "Danish", "de": "German", "el": "Greek", "en": "English", "eo": "Esperanto", "et": "Estonian", "eu": "Basque", "fa": "Persian", "fi": "Finnish", "fr": "French", "gd": "Scottish Gaelic", "ga": "Irish", "gl": "Galician", "gu": "Gujarati", "ht": "Haitian", "he": "Hebrew", "ha": "Hausa", "hi": "Hindi", "hr": "Croatian", "hu": "Hungarian", "hy": "Armenian", "ilo": "Iloko", "id": "Indonesian", "is": "Icelandic", "it": "Italian", "jv": "Javanese", "ja": "Japanese", "kn": "Kannada", "ka": "Georgian", "kk": "Kazakh", "km": "Central Khmer", "ky": "Kirghiz", "ko": "Korean", "ku": "Kurdish", "lo": "Lao", "la": "Latin", "lv": "Latvian", "lt": "Lithuanian", "lb": "Luxembourgish", "ml": "Malayalam", "mt": "Maltese", "mr": "Marathi", "mk": "Macedonian", "mg": "Malagasy", "mn": "Mongolian", "ms": "Malay", "my": "Burmese", "ne": "Nepali", "new": "Newari", "nl": "Dutch", "no": "Norwegian", "or": "Oriya", "om": "Oromo", "pa": "Punjabi", "pl": "Polish", "pt": "Portuguese", "ps": "Pushto", "qu": "Quechua", "ro": "Romanian", "ru": "Russian", "sa": "Sanskrit", "si": "Sinhala", "sk": "Slovak", "sl": "Slovenian", "sd": "Sindhi", "so": "Somali", "es": "Spanish", "sq": "Albanian", "sr": "Serbian", "su": "Sundanese", "sw": "Swahili", "sv": "Swedish", "ta": "Tamil", "tt": "Tatar", "te": "Telugu", "tg": "Tajik", "tl": "Tagalog", "th": "Thai", "tk": "Turkmen", "tr": "Turkish", "ug": "Uighur", "uk": "Ukrainian", "ur": "Urdu", "uz": "Uzbek", "vi": "Vietnamese", "yi": "Yiddish", "yo": "Yoruba", "zh": "Chinese", "zh-TW": "Chinese Simplified" }
def predict_language(model, text):
res = model.predict([text]);
pred = res[0]
lang = pred[0][0].replace('__label__', '')
if lang in supportedLanguages:
return { "LanguageCode": lang, "Score": str(res[1][0][0]) }
return {}
def lambda_handler(event, context):
text = event.get('text') or event.get('Text')
if not text:
return { "error" : "Missing text" }
# Convert fancy/artistic unicode text to ASCII (Some social media posts include fancy letters)
text = unicodedata.normalize( 'NFKC', text)
pretrained_lang_model = "/opt/pretrained/lid.176.ftz" # replace lid.176.ftz with lid.176.bin in case you use large model
model = fasttext.load_model(pretrained_lang_model)
language = predict_language(model,text);
# Return Predicted Language(s), we only return one dominant, feel free to return more.
return { "Languages" : [language]};
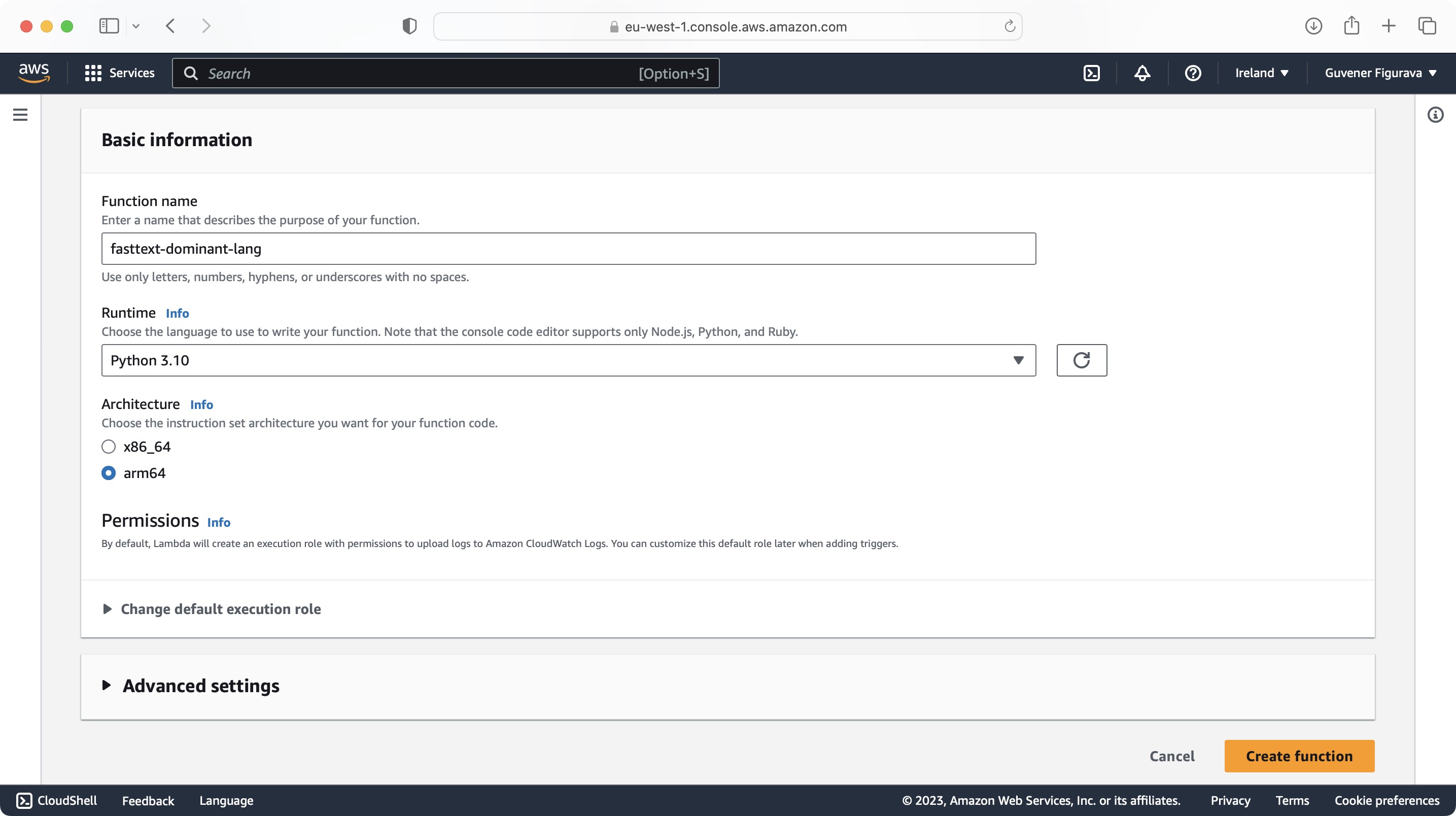
Create a lambda function in Python
Configure for Python 3.10 runtime and use arm64 architecture (if using provided layer in this repository).
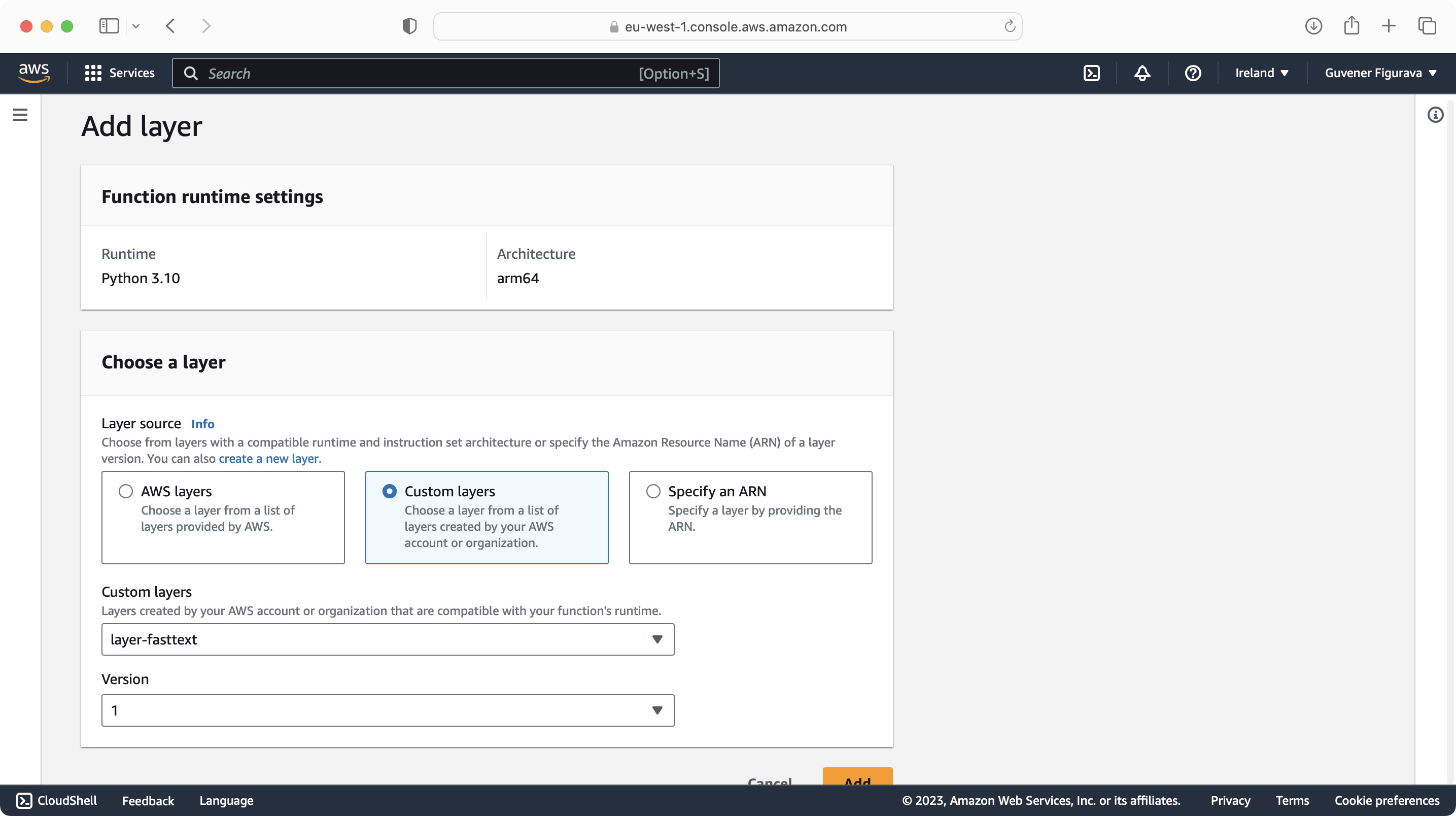
Copy handler.py contents to your function and make sure you have added both layers to your function.
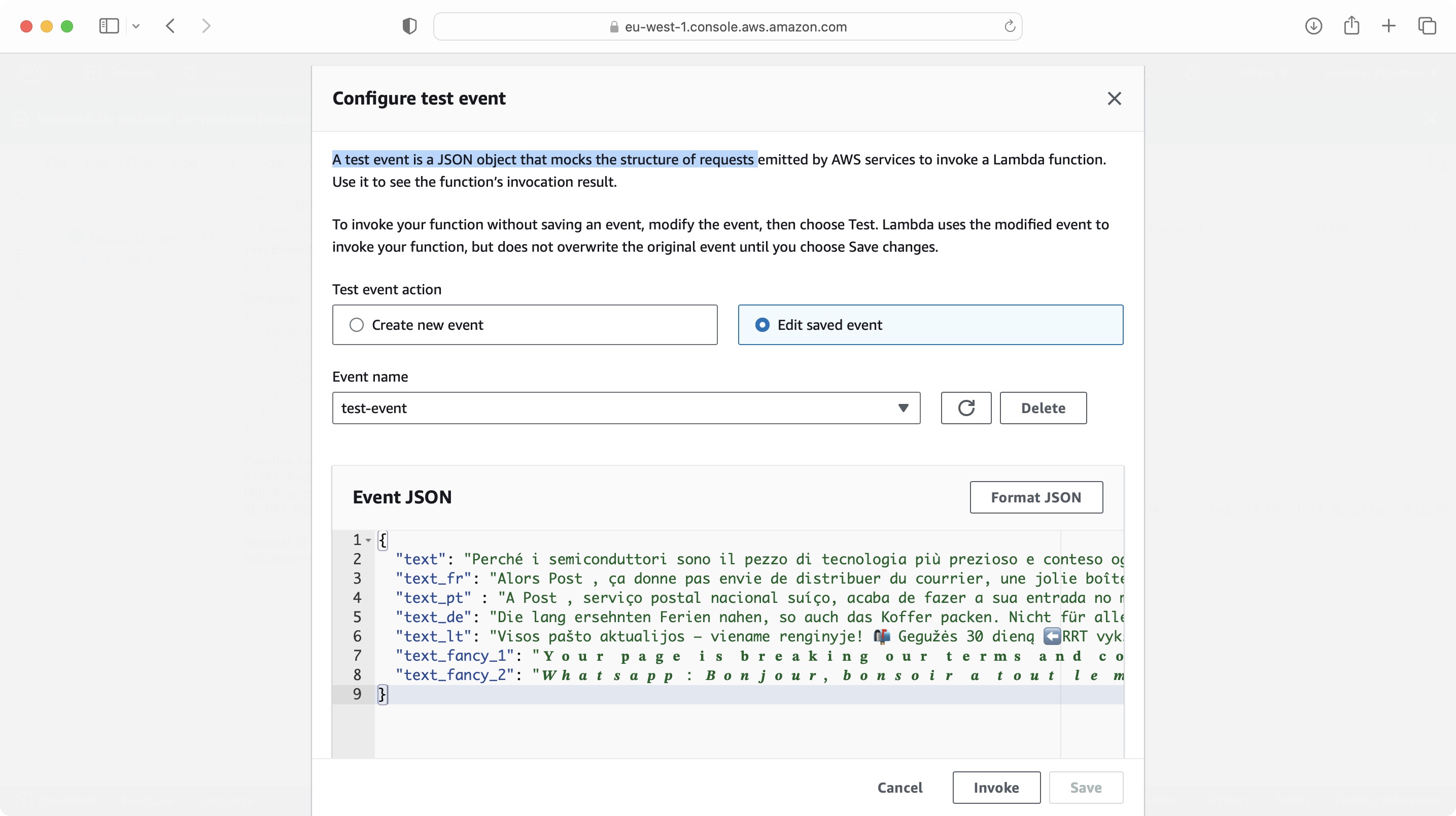
Test Request
A test event JSON object is provided in the test directory to make a test request and see the response.
{
"text": "Perché i semiconduttori sono il pezzo di tecnologia più prezioso e conteso oggi?"
}AWS Deployment Screens
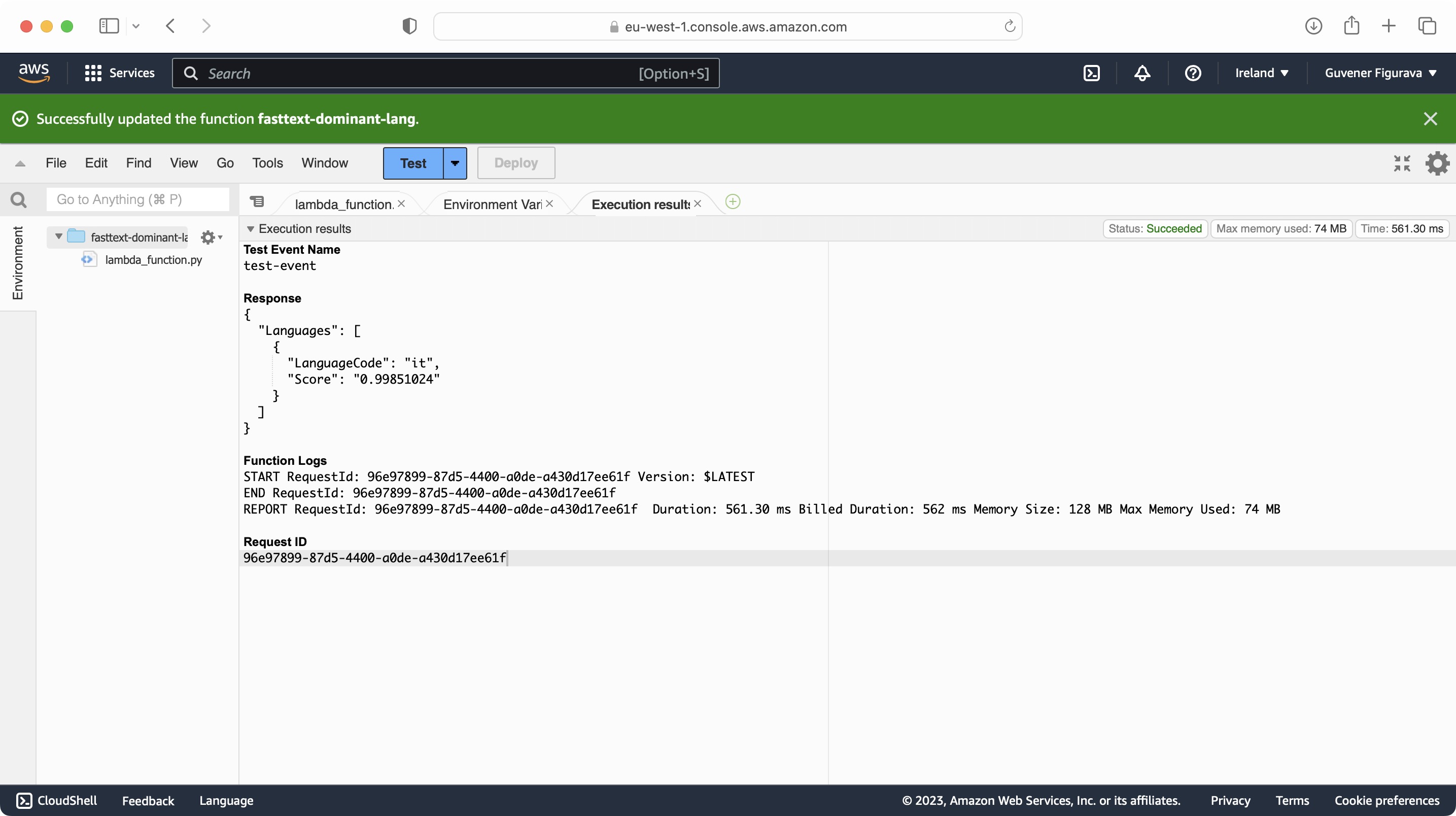
AWS resources and comparison
You may want to check AWS documentation and compare fastText responses with Comprehend, and also see the costs side by side. Here are a few links to deep dive.
- API DetectDominantLanguage Reference: docs.aws.amazon.com/comprehend
- Pricing: aws.amazon.com/comprehend/pricing
- Try on your AWS Console: console.aws.amazon.com/comprehend
Conclusion
fastText proves to be a cost-effective and efficient alternative to other managed dominant language detection services. Our tests have consistently shown that for texts over 100 characters, the detected languages are often the same as those produced by managed services such as AWS Comprehend and Google Language API.